Roller Derby, Computer Vision and AWS
In-between missions is a good time to hone your skills on your various subjects of expertise, or learn how to use new tools, or keep up with recent advances in research.
I decided to mix all these in a personal project:
- keep in touch with deep learning advances and ready-to-use models in computer vision
- get practice on architecting complex AI projects
- get practice on AWS services
- have fun doing all the previous
This project is about allowing strategy analysis in Roller Derby, by automatically extracting from video segments the position of the track, and the positions / roles / numbers of the players on it.
As this project is quite large, this post is the first in a (hopefully not that) long list of post about the modules I’ll work on.
The whole project can be found on my github : https://github.com/Xenosender/derby/
1 – What is Roller Derby ?
Origin
Roller Derby (in its actual version) is a sport that has been created in the 90’s in the US with a feminist and inclusive spirit, with a Do-It-Yourself approach : leagues are managed, coached and played by the players, and the community is very strong.
Most of the sport is at the moment in the US and English-speaking country, and mostly female.
Rules
So, what is Roller Derby ? in very brief:
- it’s a team sport
- it’s on skates
- it has contact
- there is no ball
in a little more words :
- it plays on a track which most skaters can tour in 7-9s
- it is played in 2 30min half-times, which are themselves divided in jams of at most 2mins
- at any given jam, each team aligns 5 players : 1 jammer and 4 blockers
- the jammer scores the points : 1 point each time s.he passes a blocker of the opposite team
- the blockers try to prevent the opposite jammer from scoring by blocking the way with their bodies, and help their own jammer by removing the opposite blockers of the way.
- in a jam, the first passage of each jammer does not give points, only the subsequent passages do. However, the first jammer to pass all opposite blockers becomes “lead jammer”, and is rewarded by the power of stopping the jam whenever s.he wants (which is a huge strategic advantage).
There are lots of rules about how contact is allowed (with which body parts, on which body parts) and how the game flows (basically, everyone skates counter-clockwise on the track, and that defines the relative positions of skaters and how they can initiate contact / get back on the track if they have been removed from it).
Resources
For more information, you can check wikipedia, or go to the WFTDA webpage.
Video
If you want to check what a derby match looks like :

2 – the project
I’ve been playing roller derby for a few year now, and I’m really enjoying it: the mix of contact, strategy and agility on wheels makes it a very difficult sport in which there is always a lot of room for improvement.
It is, however, a sport which has been designed to have a lot of players competing for space and passage in a small territory, and it can be quite challenging to read what is going on, even as a spectator. It is also a sport that is not well known, and thus derby matches are seldom filmed (except top leagues), and usually in an amateur way (1 fixed camera, not always with the best angle). This makes it very difficult to find and watch matches online for strategy analysis.
This is why this project has been created: I aim at creating a collection of automated systems that will allow to automatically generate from one or more videos of a given derby match a drawn representation of the track and the position of each player on it at all times during the match, aligned with the videos to make analysis easier for players and coaches.
I also aim at deploying this system on AWS, as I recently got my AWS associate architect AWS certification. This certification gave me knowledge of AWS services, but not much hands-on, which is why I intend to use AWS packages to train myself.
3 – Global architecture
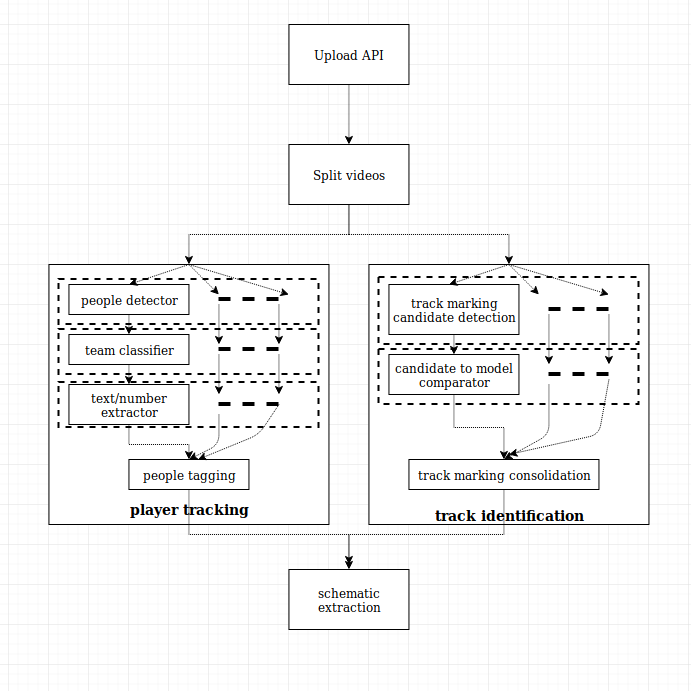
Here is a rough sketch of the chain of systems that are involved in the complete process :
There are 3 main challenges :
- finding the players
- finding the track
- putting everything together
Finding the players involves :
- finding the people in the videos
- separating the people by team A, team B, referees (there are a lot of referees in derby), and others. This supposes to leverage the fact that referees are in black and white, and that team A and team B must have different, contrasted main colors
- detect special roles (jammer, pivot) which are identifiable in each team by their helmet cover (with a star for the jammer, with a contrasted line for the pivot)
- detect the number of the players, if possible (on the back, or on the arms)
- consolidate all these information first in a single video, then cross-videos
Finding the track is a very different matter. The system will need to:
- detect candidate markings on the ground in the video
- compare it with a model of a derby track
- rank the candidates, and associate them with possible projections on the model
- consolidate in a single video, and cross-video
Finally, all information will have to be leveraged to extract the positions of all players on the track.
In a first approach, we’ll concentrate on a single jam (max 2 minutes), with a single point-of-view. In a later versions, multiple PoV could be added by adding an automatic detection of PoV change, and the processing of a whole match by detecting the changes in jams (based on sound, for example – whistle pattern detection, or post-process and find patterns in players’ motions)
AWS systems
I’ll try to make the system as serverless as possible, leveraging :
- S3 for storage
- dynamoDB for noSQL data
- lambda for automated function launch
- ECS to call and manage docker images for more complex processing
This should avoid having to monitor and provision EC2 units.
This will also allow for more parallel processing at the same cost, so that videos can be processed more quickly and scale from one jam to a whole match.
4 – Getting technical : uploading and splitting videos in 30s-long segments
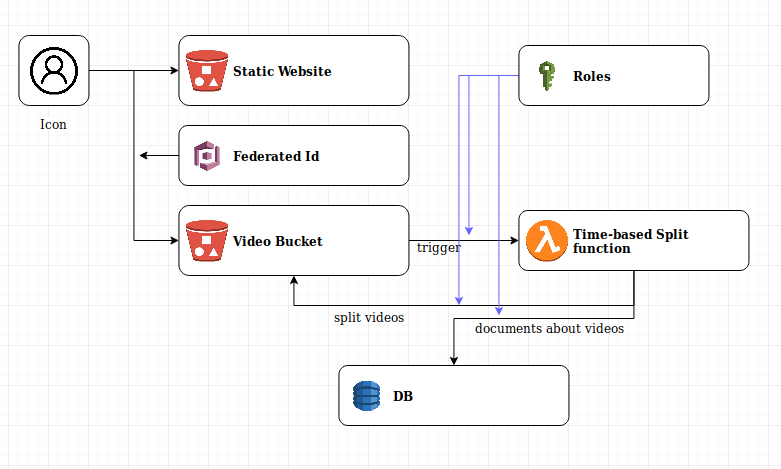
Here I describe the point of entry of the system : uploading videos to s3, and splitting them in 30s-long sub-videos. This second point is not mandatory, but allows for parallel processing of all segments if your architecture is correctly build and decoupled. If you use serverless services, the calculation cost will be the same in both cases (one big video or several small ones) but the process will be much quicker. You might have a little extra cost due to more “put” operations on s3 though.
I will focus on the architecture and the services used in the next paragraphs. Please refer to github for more details on the code itself.
a – Uploading videos : creating a static website
This covers the upload_page project.
We create here a simple, static webpage with a “choose video” button and an “upload button”. The upload button will send the chosen video to a chosen bucket, with a check on writing permissions.
For this, as I only want a very simple example site, I chose a static website hosting on s3. I thus need 2 s3 buckets :
- one for storing the uploaded videos
- one for hosting the website
From the security point of view, the first one should be private, and the second one should have public read access (since people should be able to see the page).
In order to allow the user to upload the video to a private bucket securely, I use a federated identity from the Cogito service, which creates 2 roles : one for authenticated users (that I don’t use here), and one for unauthenticated users. I then give this second role limited write access to my private s3 bucket, in a given sub-directory.
Once the AWS setup is done, I can simply update the website whenever needed using the AWS command package. It is also possible to set up an automatic deployment in CodeBuild triggered by push on github, but it’s a little overkill just for this project.
For more information on how to do all that, check upload_page/README.md
b – Splitting the uploaded video in 30s-long segments
This covers the derbyTimeSplitVideoLambda project.
Here again, we want to go serverless, and lambdas are good tools to apply simple processes automatically : it can be triggered by various events in AWS services, and can interact with other AWS services as well.
We here use the following process:
- the upload of a video in a given sub-directory triggers the call to our lambda. The generated event contains the relevant information to access the new file
- the lambda fetches the video, extract several information and creates a document in DynamoDB
- it then splits the parent video in children of max 30s. For each new child, a document is created in DynamoDB with various information and who the parent is. The child is pushed to s3 in the same bucket, but in a different path
- the DB document about the parent is uploaded with the list of the children
We thus need to setup:
- A dynamoDB table
- A lambda function
The lambda function must be given through IAM the right to read and wright to our upload bucket (for more security, read from the upload sub-directory only, and wright from another, chosen sub-directory), and to insert documents in your table.
You can then setup the trigger in your s3 bucket.
To wright and test your lambda, I develop locally using pycharm and pipenv. This necessitates that you install the boto3 library (to call AWS services from your code) and AWS command line tool (which registers your identification). As long as you’re working locally, all used rights are yours (so if you’re not admin, you should ask for the previously described rights), but once your code uploaded, it is called by the lambda service, and rights should be granted through IAM.
You should also know that the code should come with all its dependencies in a zip file, which is quite easy to do using pipenv.
Please check derbyTimeSplitVideoLambda/README.md for more details
Final architecture for these services